Advanced Python Interview Questions and Topics You Should Know
By
Samara Garcia
•

AI engineers, ML researchers, infra engineers, and LLM specialists are now expected to treat Python as a systems tool, not just a scripting language. Advanced Python interview questions increasingly test how candidates reason about performance, concurrency, and reliability in production AI systems. This guide covers the advanced topics that repeatedly appear in senior loops, including asynchronous programming, context managers, functional programming, data structures, and Python internals.
Key Takeaways
Senior Python interview questions usually include concurrency, data structures, and Python internals rather than textbook definitions.
Advanced Python interviews assess understanding of memory management and concurrency paradigms, especially in AI, ML, and infra roles.
Data science and LLM-focused roles increasingly test data types, memory behavior, vectorized computation, and performance tradeoffs inside real systems.
Structured hiring models and curated marketplaces such as Fonzi can reduce noise, but human judgment still drives final hiring decisions.
Preparation should combine targeted practice on advanced concepts with clear communication of design reasoning, tradeoffs, and real project experience.
Core Advanced Python Concepts Interviewers Rely On
Senior Python interviews usually begin with concepts that reveal whether a candidate can reason beyond syntax. Common topics include mutability, data types, scope, closures, decorators, generators, iterators, and context managers because they directly affect API design, debugging, and maintainable code. Candidates should understand how mutable and immutable objects behave, how closures and late binding can create bugs, how decorators extend functionality, and when generators are preferable to list comprehensions for memory-efficient processing.
As interviews progress, the focus often shifts to production-oriented topics such as exception handling, resource management, object-oriented design, and functional programming. Strong candidates can discuss custom exception hierarchies, async context managers, and patterns for managing files, database sessions, or network resources. Modern Python features such as type annotations, TypeVar, Protocol, structural pattern matching, and concurrent error handling in Python 3.11+ are also increasingly common in senior-level interview loops.
Asynchronous Programming, Concurrency, and the GIL
Concurrency is a common topic for backend, infrastructure, and AI-serving roles because latency and throughput directly affect system performance. Candidates should understand asyncio, event loops, coroutines, and how asynchronous code handles large numbers of network requests without blocking threads. Interview questions often compare synchronous code, async programming, threads, process pools, and task queues, especially in scenarios involving APIs, streaming systems, or model-serving workloads.
The Global Interpreter Lock (GIL) remains an important concept. In standard CPython, the GIL limits parallel execution of Python bytecode, making multiprocessing a common solution for CPU-bound workloads, while threads and async code are effective for I/O-bound tasks. Senior candidates should also understand how Python 3.14+ free-threaded builds change these tradeoffs, along with the implications for thread safety, shared state, and high-throughput services.
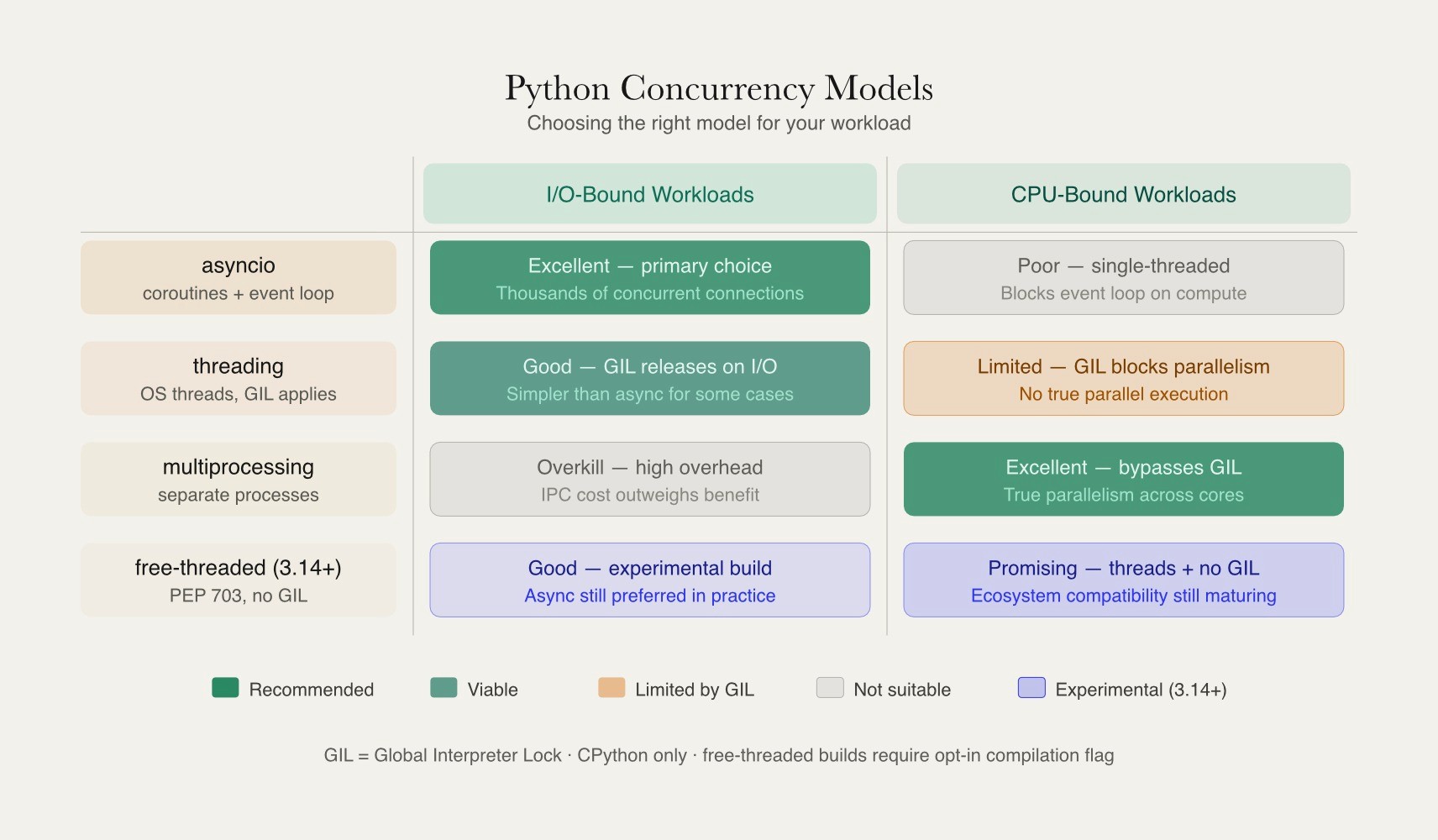
Python Internals, Memory Management, and Advanced Data Structures
Senior Python interviews often move beyond syntax into execution, memory management, and performance. Candidates should understand how CPython compiles source code into bytecode, how the Python Virtual Machine executes that bytecode, and why pure Python loops perform differently from vectorized operations in libraries such as NumPy. These concepts are especially important in machine learning, data engineering, and backend systems where allocation patterns, container choices, and unnecessary copies can affect latency, memory consumption, and throughput.
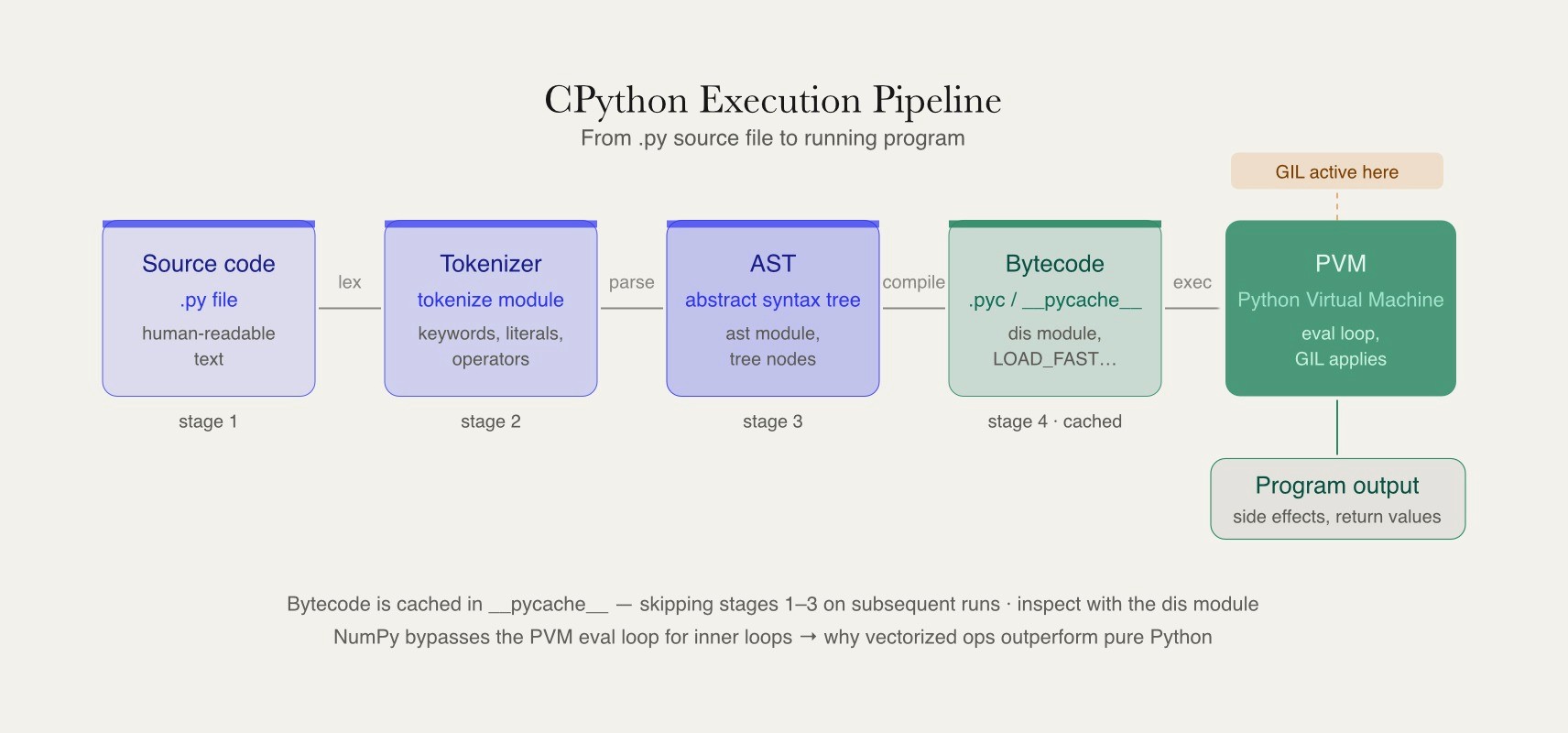
Memory management is another common topic. Python uses reference counting along with a cyclic garbage collector to reclaim unused objects, but candidates should also understand how circular references, object lifecycles, and shared memory can create performance challenges. Copy semantics are particularly important in data-intensive applications, where the difference between shallow copies, deep copies, views, and shared buffers can significantly impact both correctness and efficiency. Interviewers may also ask how Python manages objects internally and why memory behavior can differ across workloads.
Core data structures are commonly tested as well. Strong candidates should know the performance characteristics and tradeoffs of dictionaries, sets, lists, deques, heaps, and common searching and sorting techniques. Beyond algorithmic complexity, interviewers often look for practical judgment about choosing the right structure for a specific constraint. For more advanced roles, discussions may extend to descriptors, metaclasses, and Python's object model, particularly in the context of frameworks, ORMs, validation libraries, schema systems, and plugin architectures.
Advanced Topics for Data Science, ML, and LLM-Focused Python Interviews
For a data scientist or ML engineer, modern Python interview questions are rarely isolated from modeling, experimentation, and deployment. The interviewer may ask about NumPy arrays, pandas Index and MultiIndex, sparse matrices, tensors, and how memory layout affects vectorized operations.
Large datasets often force candidates to choose between eager and lazy computation. Generators allow memory-efficient iteration over large datasets, which makes generator-based loading useful for streaming ETL, online feature computation, and checkpointed training loops. Beyond numerical data, regular expressions and string manipulation remain essential context for text-heavy ML tasks, frequently appearing in practical data preprocessing, log parsing, and LLM evaluation pipelines.
Functional programming also shows up in ML pipelines. map, filter, reduce, partial application, and pure transformation functions can make preprocessing graphs reproducible, especially when paired with unit testing. The important point is not to prefer one style everywhere, but to explain why a vectorized operation, a Python loop, or a composed pipeline is the right tradeoff.
Context managers appear again in ML-specific settings. Candidates may be asked to manage CUDA memory, experiment tracking sessions, temporary datasets, model checkpoints, or transactional writes. LLM and retrieval-augmented generation systems add another layer, since batched retrieval, embedding calls, and flaky model endpoints require robust exception handling around timeouts, partial failures, and retries.
Mapping Advanced Python Topics to Typical Interview Questions
Use this table as a checklist for prioritizing preparation time. Many senior loops include 100+ advanced questions across categories, but most evaluate the same underlying technical knowledge.
Topic | Example Interview Question | Role Types That Ask This | What Interviewers Look For |
Asynchronous programming and event loops | Design an async client for vector DB calls with retries and rate limits. | LLM infra, backend, platform | Correct use of tasks, cancellation, backpressure, and TaskGroups. |
Context managers and resource safety | Implement a context manager for safe checkpoint writes or GPU handles. | ML engineering, infra | Cleanup on failure, clear ownership, readable code. |
Advanced data structures and algorithms | Choose between dict, set, deque, heap, or binary search for a streaming service. | Backend, data infra | Complexity, constant factors, memory-efficient choices. |
Exception handling patterns | Handle multiple async failures with Exception Groups and except*. | Distributed systems, serving | Robust error handling and partial failure reasoning. |
Python internals and memory management | Explain reference counting, garbage collection, and copy behavior for large tensors. | Data science, ML systems | Practical memory management, not trivia. |
GIL and free-threaded Python | Compare threads, processes, async I/O, and Python 3.14+ free-threaded builds. | Infra, performance, serving | Understanding that the GIL matters differently for I/O-bound and CPU-bound workloads. |
How to Prepare Effectively for Advanced Python Interviews
Senior practitioners already know Python, so preparation should focus on targeted refinement around the advanced features interviewers ask about. Start by reviewing canonical documentation for asyncio, the data model, context managers, typing, and PEP 703, then implement small utilities that force you to use those concepts.

A practical study cycle might include rewriting a synchronous service into an asyncio-based one, implementing custom context managers, profiling memory usage, and adding unit testing around failure cases. You can also build a small portfolio of artifacts: an async API client, a streaming data loader, a typed plugin interface, or a benchmark comparing threads, processes, and vectorized code.
During mock interviews, rehearse explaining design tradeoffs in non-hand-wavy language. Discuss why you chose a data structure where concurrency improves throughput, how you would test failure paths, and what you would measure before optimizing. If you use a structured platform such as Fonzi, look for interview loops where deep Python skills are valued and where human hiring managers still assess long-term fit.
Finding Senior Python Engineers Through Match Day
As organizations scale AI infrastructure, model-serving platforms, and data-intensive applications, hiring teams increasingly look for engineers who can demonstrate deep Python expertise beyond scripting. Senior candidates who understand concurrency, memory management, asynchronous programming, and production reliability are often difficult to identify through resumes alone. Fonzi helps connect employers with vetted engineers who have experience building distributed systems, ML platforms, backend services, and high-performance Python applications, allowing teams to spend less time sourcing and more time evaluating technical fit.
Match Day can also help surface candidates whose strengths align with the advanced Python skills commonly evaluated in senior interview loops. Rather than relying exclusively on inbound applications, employers can meet engineers who have worked on async services, large-scale data pipelines, LLM infrastructure, vector databases, and performance-sensitive systems. This is particularly relevant for teams building AI infrastructure, ML platforms, or high-throughput backend systems, where Python concurrency and memory management directly affect production reliability.
Summary
Advanced Python interviews in 2026 focus on how engineers use Python in production systems rather than their ability to recall language syntax. Senior candidates are expected to understand concurrency, asynchronous programming, memory management, data structures, exception handling, context managers, typing, and Python internals. Interviewers often assess how candidates reason about performance, scalability, reliability, and maintainability, particularly in AI, machine learning, backend, and infrastructure environments.
Common topics include asyncio, event loops, the Global Interpreter Lock (GIL), multiprocessing, generators, decorators, closures, and CPython internals such as bytecode execution and garbage collection. Data-focused roles may emphasize NumPy, pandas, vectorized computation, memory-efficient processing, and large-scale data handling, while infrastructure roles often focus on concurrency, resource management, and fault tolerance. Strong candidates can explain technical trade-offs clearly, choose appropriate data structures and concurrency models, and connect advanced Python concepts to real-world systems, performance requirements, and production reliability challenges.
FAQ
How deep do I need to go into Python internals for senior AI or ML roles?
Should I prioritize asynchronous programming or advanced data structures when preparing?
How often do metaclasses and descriptors come up in real interviews?
Can I rely on AI tools during take-home Python assignments?
How can I demonstrate advanced Python skills without open source contributions?



