What Are Embeddings? Machine Learning Embeddings Explained Simply
By
Samantha Cox
•

Imagine it’s early 2026 and you’re a founder or hiring lead staring at 2,000 AI engineer profiles. Many look impressive on paper, but it’s hard to tell who can actually ship a production-ready RAG system versus who’s only experimented in notebooks. Titles and brand-name companies don’t answer the real question: who can build what your product needs right now?
That’s where embeddings come in. Embeddings turn messy, real-world signals, text, code, GitHub repos, and portfolios into structured data that can be meaningfully compared. They’re why search understands intent, why recommendations feel intuitive, and increasingly, why modern hiring tools can match real skills to real problems. Fonzi uses this same foundation to power skills-first AI hiring, helping recruiters and founders cut through surface-level credentials and identify engineers who can actually deliver in production. If you want a practical understanding of how embeddings work and how they’re reshaping AI hiring, this is the context that matters.
Key Takeaways
Embeddings transform raw data into a mathematical structure. Instead of treating words or images as disconnected symbols, embeddings place them in a continuous vector space where distance reflects similarity.
Modern AI hiring platforms like Fonzi use embeddings to evaluate how candidates actually think and code. This goes far beyond resume keyword matching; embeddings capture semantic relationships between skills, projects, and problem-solving approaches.
Fonzi delivers elite AI hires in approximately 3 weeks. By combining embeddings with structured, repeatable technical evaluation, the platform creates consistent, scalable hiring pipelines.
Embeddings make hiring scalable at any stage. Whether you’re making your first ML engineer hire at a seed-stage startup or filling thousands of AI roles in a global enterprise, embedding-driven matching handles the complexity.
This technology powers the AI tools you already use. From search and chatbots to recommendations and fraud detection, embeddings are the invisible infrastructure behind intelligent systems.
Embeddings 101: What They Are and How They Work
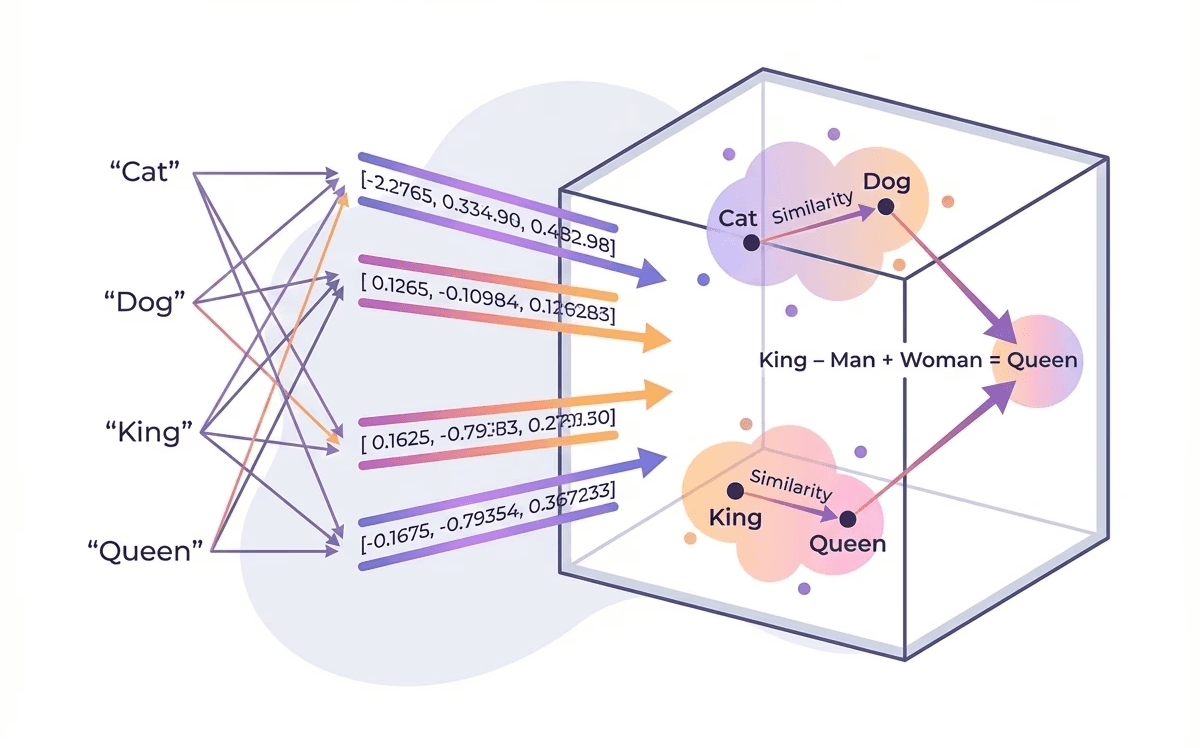
At its core, an embedding is a dense vector representation of something, a word, a sentence, an image, a user, expressed as a list of numbers. These aren’t random numbers. They’re learned coordinates in a high-dimensional space where “nearby points mean similar things.”
Think of it this way: in embedding space, the numerical vectors for “Python,” “PyTorch,” and “TensorFlow” end up close together because they frequently appear in similar contexts and represent related concepts. Meanwhile, “cat” or “football” sit far away in this multi-dimensional space because they have little semantic overlap with programming frameworks.
How do these vector representations get learned? Neural networks process massive training data: billions of tokens for language models, millions of images for vision systems, and gradually adjust the embedding layer to capture meaningful patterns. The model learns that words appearing in similar contexts should have similar embeddings. Over time, this process creates a continuous vector space where semantic similarity translates to geometric proximity.
What’s remarkable is what this process throws away. Embeddings are a form of lossy compression. The model keeps what matters for downstream tasks, meaning, semantic and syntactic relationships, and conceptual patterns, and drops surface details like exact wording, formatting, or noise. This is why embeddings capture semantic relationships that keyword matching completely misses.
Compare this to traditional feature engineering. In the old approach, humans would hand-craft features: count keyword occurrences, build TF-IDF scores, and define rules. This required deep domain expertise and produced sparse, brittle representations. Embeddings flip the script. The neural networks learn dense vector representations automatically, discovering complex relationships that human engineers would never explicitly encode.
A famous example illustrates the power here. Word2Vec, introduced in 2013, demonstrated that vector arithmetic could solve analogies: the embedding for “king” minus “man” plus “woman” approximately equals “queen.” This wasn’t programmed; it emerged from the model learning word representation patterns in natural language. BERT (2018) extended this to contextual embeddings, where the same word gets different vectors based on the surrounding context. CLIP (2021) unified text and images into the same embedding space, enabling zero-shot image classification.
Core Types of Embeddings: Words, Sentences, Code, Images, and Beyond
Modern machine learning models don’t just embed words. They embed almost everything: sentences, documents, code, images, users, items, and even graph data. Each type serves different applications, but they share the same core principle, transforming complex data types into dimensional vectors where similarity becomes measurable.
Word embeddings: represent individual tokens as fixed vectors. Classic models like Word2Vec and GloVe assign each word a single vector (typically 300 dimensions) based on co-occurrence patterns in massive corpora. In these spaces, “doctor” sits close to “nurse” and “physician” because they appear in similar contexts. The limitation? These are static; the word “bank” gets the same vector whether you mean a river bank or a financial institution. This is where one-hot encoding falls short and dense embeddings shine.
Sentence and document embeddings: solve the context problem by representing entire chunks of textual data as single vectors. Models like Universal Sentence Encoder (2018), Sentence-BERT (2019), and OpenAI’s text embeddings can encode a full paragraph, email, or support ticket into one numerical representation. This powers semantic search: your query “how do I reset my password” matches documentation about “account recovery steps” because the text embeddings are close in vector space, even with zero word overlap. Document embeddings extend this to longer content.
Code embeddings: treat source code as its own language. Models like CodeBERT (2020) and StarCoder (2023) learn vector representations of code snippets, enabling powerful searches like “find all functions that validate JWT tokens” across entire repositories. These models understand that a Python authentication function and a JavaScript login validator might be semantically similar despite syntactic differences. This capability is transforming how engineering teams navigate large codebases.
Image and multimodal embeddings: bring visual content into the same mathematical structure. Convolutional neural networks like ResNet extract hierarchical features from pixels into high-dimensional vectors. Vision Transformers (ViTs) achieve similar results with attention mechanisms. CLIP (2021) goes further, training on 400 million image-text pairs to place images and text in a shared embedding space. The text “a red sports car” sits close to actual images of red sports cars, enabling zero-shot image classification and cross-modal search.
User and item embeddings: power the recommendation systems you interact with daily. Netflix, Spotify, and Amazon learn lower-dimensional representations for users and products based on interaction patterns. Users who watch similar movies get similar embeddings. Products frequently purchased together cluster in dimensional space. When the system recommends “customers like you also bought,” it’s finding items whose embeddings are close to your user embedding, a form of graph embedding applied to interaction networks.
Graph embeddings: extend these concepts to network structures. Node2Vec (2016) and GraphSAGE (2017) learn embeddings for nodes in social networks, knowledge graphs, or transaction networks by preserving structural relationships. A fraudster’s transaction patterns might look normal in isolation but create embeddings far from typical users when the full network is considered. This enables node classification and anomaly detection at scale.
How Embeddings Power Real-World AI Systems in 2026

Embeddings are the invisible infrastructure inside many tools that founders already use daily. When you search your company’s internal documentation, ask a chatbot a question, get a product recommendation, or trigger a fraud alert, embeddings are doing the heavy lifting behind the scenes.
Understanding this helps you appreciate both what modern AI can do and where hiring platforms like Fonzi fit in the landscape. The same techniques that make your search bar smart are now being applied to match AI engineers to roles.
Example Table: How Embeddings Change Product Behavior
The following table illustrates the concrete difference that embeddings make across common use cases:
Use Case | Without Embeddings | With Embeddings | What It Feels Like to the User |
Internal documentation search | Matches only exact keywords; “JWT” doesn’t find “login token” | Understands “login token” ≈ “JWT” ≈ “authentication credential” | Find answers even when you don’t know the exact terminology |
Customer support chatbot | Rigid decision trees; fails on paraphrased questions | Recognizes intent regardless of phrasing; retrieves relevant context | Actually helpful responses that understand your question |
Product recommendation | “Customers who bought X also bought Y” based on purchase overlap | Similar users and similar items cluster in embedding space | Surprisingly relevant suggestions, even for niche interests |
Fraud detection | Rule-based thresholds; misses novel patterns | Transaction and behavior embeddings reveal outliers in vector space | Legitimate transactions go through; suspicious ones get flagged |
Technical hiring/matching | Keyword matching on job titles and listed skills | Embeddings capture coding patterns, project complexity, and problem-solving style | Candidates matched on actual capability, not resume formatting |
Semantic search transforms how users find information. Traditional keyword search requires users to guess the exact terms used in documentation. With embeddings, a natural language query like “how do I handle rate limits in the API?” retrieves the right paragraph even if the documentation uses “throttling” or “request quotas.” The query and documents are converted to embedding vectors, and cosine similarity identifies the closest matches in the continuous vector.
Retrieval-augmented generation (RAG) combines embeddings with large language models to reduce hallucination. When you ask an LLM about your company’s specific product, the system first uses embeddings to retrieve relevant internal wiki pages, product specs, or documentation. The LLM then generates answers grounded in that retrieved context. Studies show this approach reduces hallucination by around 40% compared to pure generation, a critical capability for enterprise AI applications.
Recommendation systems embed users and items to power personalization at scale. Rather than relying only on explicit ratings, modern systems learn dense vector representations from behavioral data. Your implicit preferences, such as what you click, how long you watch, and what you skip, shape your user embedding. Items are embedded based on their attributes and the users who engage with them. Recommendation becomes nearest-neighbor search: find items whose embeddings are close to yours.
Anomaly and fraud detection leverages the geometric properties of the embedding space. Normal transactions, user behaviors, and device patterns cluster together. Fraudulent activities, even novel attack patterns the system hasn’t seen before, often produce embeddings that are outliers, far from the normal clusters. PayPal processes millions of transactions daily using embedding-based fraud detection, identifying suspicious patterns that rule-based systems would miss.
All of these applications rely on fast approximate nearest-neighbor search. Finding the closest vectors among millions requires specialized algorithms and infrastructure. Tools like FAISS (developed by Facebook AI in 2017), Annoy, and vector databases like Qdrant and Pinecone enable sub-millisecond searches across billions of vectors. The computational power required has become accessible enough that startups can now build embedding-powered features that only tech giants could afford five years ago.
From Embeddings to Better Hiring: How Fonzi Works

Hiring elite AI engineers is now an AI problem. You need to understand a candidate’s capabilities in a high-dimensional space: their technical skills, depth of experience, tooling fluency, research literacy, collaboration style, and ability to ship production systems. Resumes and keyword matching capture almost none of this.
Fonzi is an AI-powered hiring platform that uses embeddings plus structured assessments to evaluate engineers objectively at scale. Here’s how the system works:
Candidate intake starts by converting candidate materials into rich embeddings. Fonzi ingests resumes, GitHub and Bitbucket repositories, Kaggle profiles, and prior project descriptions. Natural language processing models generate embeddings that capture domains (NLP, computer vision, reinforcement learning), skill depth, technology preferences, and project complexity. This goes far beyond parsing keywords; the system understands that someone who built a production recommendation system has different capabilities than someone who completed a tutorial.
Technical evaluation produces the most valuable embeddings. Candidates complete practical, time-bounded tasks designed to reflect real work: implementing a retrieval-augmented QA system, optimizing a PyTorch model for inference, and debugging a data pipeline. These aren’t algorithmic puzzles with no connection to actual ML engineering. The submitted work, code, architecture decisions, and reasoning traces get converted into embeddings that capture code quality, system design thinking, and problem-solving patterns. Deep learning models analyze how candidates approach ambiguity, handle edge cases, and communicate technical decisions.
Company profile embeddings capture what you’re actually looking for. Fonzi builds embeddings for each role and company context, including tech stack (are you using Kubeflow or simple EC2 instances?), MLOps maturity, company stage (seed versus Series D), team structure, and goals (“productionize LLM features in Q1 2026”). This ensures matching accounts for fit, not just capability. A researcher thriving at a large lab might struggle at a scrappy startup that needs someone to wear multiple hats.
Matching engine brings these embeddings together. Using the candidate skill embeddings and role requirement embeddings, Fonzi identifies candidates whose vectors are genuinely close, not just keyword matches, but actual capability alignment. The system can distinguish between someone who “worked on NLP” and someone who designed and deployed production NLP systems at scale.
This process typically leads to hires within approximately 3 weeks. The platform handles both the first AI hire at a 5-person startup and large enterprise cohorts with equal rigor. Whether you’re building a small founding ML team or scaling to thousands of AI practitioners, the embedding-driven approach adapts.
Why Embeddings Make Fonzi Fast, Consistent, and Scalable
Traditional hiring relies on manual resume screens, inconsistent interviews, and interviewer bias. One interviewer might love a candidate’s GitHub projects while another dismisses them for lacking a specific degree. Scoring varies by interviewer's mood, time of day, and whether the previous candidate was particularly strong or weak. Embedding-based evaluation standardizes and scales this process.
Fast means drastically reduced time-to-shortlist. Instead of manually reviewing hundreds of applications, Fonzi’s embedding pipeline instantly identifies candidates whose vectors are close to the role requirements. Semantic similarity scores surface the most promising candidates in hours, not weeks. This drives typical hire timelines under 3 weeks, compared to industry averages of 6-12 weeks for senior ML roles.
Consistent means every candidate passes through the same evaluation pipeline. Their work products, profiles, and assessment submissions all get converted to embeddings using the same models. This creates comparable signals across applicants, regardless of resume formatting, self-promotion ability, or interview day luck. Machine learning algorithms apply the same criteria to everyone.
Scalable means handling volume without sacrificing quality. Once the embedding and evaluation pipelines are in place, the difference between processing 10 candidates and 10,000 is primarily compute cost, not interviewer bandwidth. Recurrent neural networks and transformer models can evaluate code quality at scale; dimensionality reduction techniques keep vector operations efficient.
Fonzi also adapts over time. The system learns from hiring outcomes, updating role embeddings based on which candidates succeeded versus those who didn’t work out. Fine-tune the model based on your specific hiring patterns, and matching improves with each hire.
Consider three scenarios:
Early-stage: A seed-stage startup in 2026 needs its first ML engineer to build an MVP recommendation engine. The founders don’t have technical interviewing experience for ML roles. Fonzi’s embeddings capture what “good” looks like based on thousands of prior evaluations, giving the startup enterprise-grade assessment capability from day one.
Growth-stage: A Series C company needs to hire 20 applied ML engineers to build a multi-region personalization system. Interviewer bandwidth is the bottleneck. Fonzi’s consistent evaluation pipeline ensures all 20 hires meet the same bar, even as different team members participate in final rounds.
Enterprise: A global bank is standing up a 500+ person AI organization for risk modeling and customer intelligence. Hiring at this scale requires programmatic evaluation. Embedding-driven matching handles the complexity, creating embeddings for dozens of specialized roles and matching against thousands of candidates.
Keeping Candidate Experience Front and Center

A common fear with AI-powered hiring is that automation makes the process feel dehumanizing or opaque. Candidates worry they’re being filtered by black-box algorithms that miss their true potential.
When used correctly, embeddings actually enable a richer understanding of candidates. Consider a self-taught researcher who contributed to major open-source projects but lacks a traditional CS degree. Keyword-based resume filters might reject them immediately. Embedding-based evaluation recognizes that their GitHub contributions demonstrate the same (or greater) capability as candidates with prestigious credentials. Embeddings capture what matters, being demonstrated skill, not proxy signals.
Fonzi structures candidate experience around transparency and relevance:
Role-relevant tasks reflect actual work. Candidates aren’t solving inverted binary tree puzzles that have nothing to do with ML engineering. Instead, they might design an evaluation strategy for a question-answering model, optimize inference latency for a production system, or architect a data pipeline for a specific use case. This respects candidates’ time and gives them a useful signal about what the role actually involves.
Consistent evaluation creates fairness. Every candidate’s work is evaluated by the same embedding and scoring pipeline. This eliminates the inconsistency where one interviewer gives easy questions while another asks impossible ones. Candidates from non-traditional backgrounds, different geographies, or less prestigious previous employers get the same objective evaluation.
Feedback loops become possible when you have structured data. Patterns in embeddings, recurring strengths in system design, and common gaps in production experience can inform structured feedback to candidates and hiring teams. This transforms hiring from a black hole where candidates never hear back into a process that respects everyone’s investment.
Embeddings enable personalization that improves long-term retention. By matching candidates to roles where their genuine strengths, research, infrastructure, and productization are the best fit, you’re not just filling seats. You’re building teams where people can do their best work.
Conclusion: Embeddings as the Quiet Engine Behind Modern AI Hiring
At a high level, embeddings are the numeric language AI uses to understand similarity between words, code snippets, images, and even people and roles. They convert messy, unstructured data into vectors where distance actually means something, making it possible to compare intent, skill sets, and patterns in a precise way. This is the same foundation behind the AI products teams rely on every day: semantic search that understands what you mean, recommendations that feel personal, chat systems that stay on track, and fraud detection that catches new, never-before-seen behavior. Thanks to widely available pretrained models like BERT and CLIP, embeddings are no longer locked inside research labs. they’re practical tools for real businesses.
That same approach is now reshaping how AI teams hire. Fonzi uses embedding-driven evaluation to match candidates to roles based on demonstrated skills, not just titles or keywords, which is how many teams are able to make strong AI hires in roughly three weeks. Evaluations stay consistent as you scale, from your first ML hire to hundreds of engineers, while candidates get clearer, more role-relevant signals about fit. If you’re a founder, CTO, or AI leader, it’s worth seeing this in action: a short Fonzi demo can show how embedding-based matching would work for your specific roles and how to pilot it on one or two openings before scaling.
FAQ
What are embeddings in machine learning and how do they work?
What is an embedding model and how is it created?
What are the different types of embeddings (word, sentence, image)?
How are embeddings used in real-world AI applications?
What’s the difference between embeddings and traditional feature engineering?



